��(d��ng)ǰλ�ã����(y��) > Ƕ��ʽ��Ӗ(x��n) > Ƕ��ʽ�W(xu��)��(x��) > �v������ > ��ʲô��Ҫͬ����
 ��ʲô��Ҫͬ����
�r(sh��)�g��2018-09-26 ��(l��i)Դ��δ֪
��ʲô��Ҫͬ����
�r(sh��)�g��2018-09-26 ��(l��i)Դ��δ֪
1. ��ʲô��Ҫͬ����
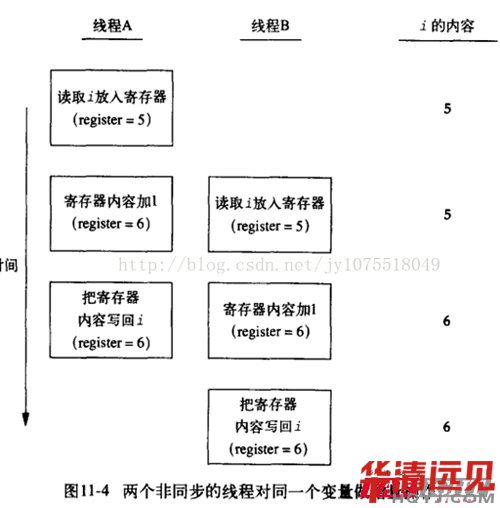
����ĈD�Ǐġ���(j��)���̡��нصĈD���mȻ����ᘌ�(du��)���̵ģ������@��Ҫ�f(shu��)�������H�H����Ҫ���]�@��(g��)��(w��n)�}��ֻҪ�漰�����l(f��)�ij���Ҫ���]ͬ����������M(j��n)�̹����(n��i)�棬����ij��(g��)�(q��)��(d��ng)��(hu��)ͬ�r(sh��)�����_(k��i)�����ҕ�(hu��)���ׂ�(g��)�M(j��n)��ͬ�r(sh��)���(q��)��(d��ng)�е�ֵ���Ĵ���......
ԭ���϶���һ�ӵģ��ྀ�̲��l(f��)�L��(w��n)��һ��Ҫע��ģ���?y��n)�ͬһ�M(j��n)�̵Ķ���(g��)���̱��������M(j��n)���YԴ�����f(shu��)׃���ă�(n��i)�档�����ψD��(l��i)�f(shu��)���҂���(du��)i׃����ֵ+1��������ô�@��(g��)��(ji��n)��(ji��n)�Άε�+1������������CPU�ϕ�(hu��)��ô��(zh��)����?ͨ���֞�3����
(1) �ă�(n��i)���Ԫ�x��Ĵ���
(2) �ڼĴ������M(j��n)��׃��ֵ����
(3) ���µ�ֵ��(xi��)��(n��i)���Ԫ
�@�͌�(d��o)�����ψD�Ć�(w��n)�}��A�����ڰ�i�ă�(n��i)���x��Ĵ�����׃�^(gu��)����(߀�](m��i)��(xi��)�ص���(n��i)��)��B����Ҳ��(du��)i����ͬ�Ӳ����������ں�Y(ji��)�������x��Ķ���5����(xi��)��Ķ���6����ô����(l��i)�҂���Ҫ��(du��)i����2�εģ���(sh��)�H�s������1�Ρ��@�N�����r(sh��)�g��(w��n)�}���ܰl(f��)����ns��(j��)�e�������Ԯ�(d��ng)��̎������(d��ng)�m��GHZ���ٶȁ�(l��i)�f(shu��)���l(f��)���@�N��r����߀�Ǻܴ�ġ�
2.�(y��n)�Cԇ�(y��n)
�����҂�������(sh��)�(y��n)��(l��i)��(sh��)�H�����@�N��r��
���³���
1. #include
2. #include
3. #include
4. #include
5.
6. #define NUM 40000000
7.
8. pthread_t tid1;
9. pthread_t tid2;
10.
11. unsigned int count1 = 0;
12. unsigned int count2 = 0;
13. unsigned int count = 0;
14.
15. void * thr_fn1(void *arg)
16. {
17. while(count1
18. {
19. count++;
20. count1++;
21. }
22. }
23.
24. void * thr_fn2(void *arg)
25. {
26. while(count2
27. {
28. count++;
29. count2++;
30. }
31. }
32.
33. int main(void)
34. {
35. int err;
36.
37. err = pthread_create(&tid1, NULL, thr_fn1, NULL);
38. if (err != 0)
39. perror("can't create thread1");
40.
41. err = pthread_create(&tid2, NULL, thr_fn2, NULL);
42. if (err != 0)
43. perror("can't create thread2");
44.
45. pthread_join(tid1, NULL);
46. pthread_join(tid2, NULL);
47.
48. printf("count = %u, count1 = %u, count2 = %u\n", count, count1, count2);
49. exit(0);
50. }
����ܺ�(ji��n)�Σ����DŽ�(chu��ng)���ɂ�(g��)���̣�Ȼ��ÿ��(g��)���̷քe��(du��)count����40000000 ֵ���@��(g��)ֵ�����S���x�ģ�ֻҪ��һ�c(di��n)���У����DŽe����2^32����count1��count2�քe��(l��i)ӛ䛃ɂ�(g��)���̌�(du��)count�քe�����˶��ٴΣ��䌍(sh��)��NUM���ƾͺ��ˣ����^(gu��)���ˌ�(du��)�ȣ��҂������@�ɂ�(g��)׃�������M(j��n)�̄�(chu��ng)���ɂ�(g��)���̺��҂���pthread_join����(sh��)��(l��i)�ȴ��ɂ�(g��)���̈�(zh��)���ꮅ������ӡ����(g��)ֵ���^�ó��Y(ji��)����
������PC�C(j��)�Ͽ��½Y(ji��)����CPU���p��2.6GHZ�ģ��\(y��n)�Эh(hu��n)����ubuntu��혱���time����鿴��(zh��)�Еr(sh��)�g��
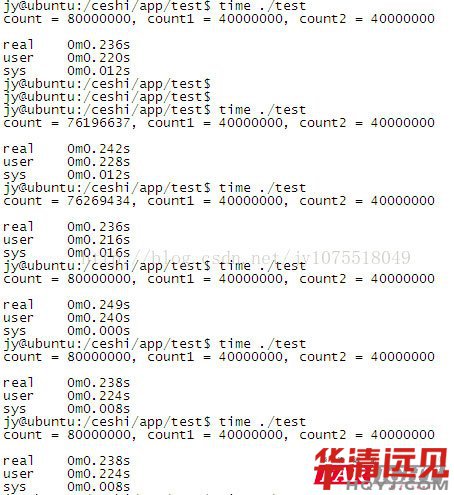
���ψD���Կ������ɂ�(g��)���̌�(du��)count�M(j��n)�п���80000000���ۼӴ����Ҫ2ms��һ�c(di��n)���y(c��)��6����2�����І�(w��n)�}�ģ���count != count1 + count2������߀�DZ��^��ġ�
Ȼ���Ұ���ͬ�Ĵ��a���¾��g�õ�AM335x(TI A8�κ�600MHZ)�\(y��n)�У��Y(ji��)������
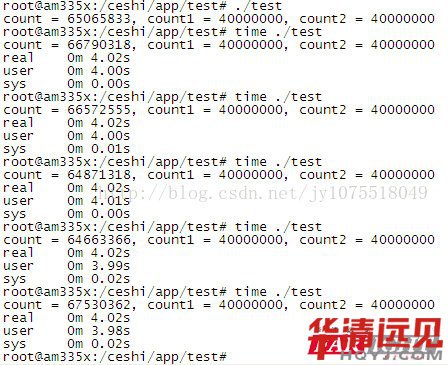
�@��(g��)�r(sh��)�g����ĕr(sh��)�����@�L(zh��ng)�ˣ���Ҫ���4s������(l��i)���Ԟ�κ�̎�������e(cu��)���ʕ�(hu��)С���](m��i)�뵽�\(y��n)��5�νY(ji��)����Ȼȫ���e(cu��)�ġ����w��ʲô��(hu��)�@�ӛ](m��i)ȥ������둪(y��ng)ԓ��SMP�C(j��)�Ƽ�����ϵ�y(t��ng)�����{(di��o)�����P(gu��n)���@��(g��)�Y(ji��)�����C���˾���ͬ������Ҫ�ԣ���������Ƕ��ʽϵ�y(t��ng)�С�
3.ͬ����(w��n)�}��Q����
��Ȼ��(w��n)�}�������ˣ�����(l��i)��(d��ng)Ȼ�ǽ�Q�����ˣ���Q�@�Nͬ����(w��n)�}��(j��ng)��ķ��������i�ˣ����Ŵ���ƽ�r(sh��)�����^(gu��)����linux���̎�(k��)�ṩ�Ľӿڣ����a�Ğ�������ʽ��
1. #define NUM 40000000
2. pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
3.
4. pthread_t tid1;
5. pthread_t tid2;
6.
7. unsigned int count1 = 0;
8. unsigned int count2 = 0;
9. unsigned int count = 0;
10.
11. void * thr_fn1(void *arg)
12. {
13. while(count1
14. {
15. pthread_mutex_lock(&lock);
16. count++;
17. pthread_mutex_unlock(&lock);
18.
19. count1++;
20. }
21. }
22.
23. void * thr_fn2(void *arg)
24. {
25. while(count2
26. {
27. pthread_mutex_lock(&lock);
28. count++;
29. pthread_mutex_unlock(&lock);
30.
31. count2++;
32. }
33. }
ֻ�г��˲��ִ��a�������Ķ�һ�ӣ��䌍(sh��)˼��ܺ�(ji��n)�Σ������ڲ��l(f��)�L��(w��n)ͬһ��(g��)׃���r(sh��)�o�@��(g��)����׃�����i�����C��(xi��)������ԭ���Լ��ɡ���ô��ʲôcount1��count2���ü��i�أ���?y��n)�ɂ�(g��)׃��������ֻ�ڃɂ�(g��)�����зքe���������ԛ](m��i)��Ҫ���i��
���(l��i)���½Y(ji��)������(w��n)�}�����ѽ�(j��ng)��Q�ˣ������@�����c(di��n)���ڽY(ji��)���ϣ����ڳ����(zh��)�Еr(sh��)�g�ϡ��@����PC�ϽY(ji��)����
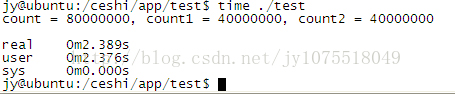
�@����ARM�ϵĽY(ji��)����

�����@��(g��)������PC��ͬһ�����\(y��n)�Еr(sh��)�g����10���������϶���6�������Լ��i�����ڱ��C�˲��l(f��)�L��(w��n)���_��ͬ�r(sh��)����������˳����\(y��n)�Еr(sh��)�g�������҂�?c��)ڶ��M(j��n)�̹����YԴ���l(f��)�L��(w��n)�����O(sh��)Ӌ(j��)�r(sh��)����Ҫ�C�Ͽ��]��������_�Ժ�Ч�ʡ�

 11�¾͘I(y��)�L(f��ng)�ư�ح���н�Y18k����н11k�����¾͘I(y��)���c(di��n)ʮ�¾͘I(y��)�L(f��ng)�ư�ح�x���A�� ��н�͘I(y��)�����ܶ����@���¾͘I(y��)�L(f��ng)�ư� | �͘I(y��)�΄�(sh��)���ԣ��A��W(xu��)�Ӆs���(sh��)��������T�ܿɐ�(��i) ���YҲ���� 8��н�Y���t��һ�N���������e�˼ҵij���T����һ�N���YҲ�����e�����¾͘I(y��)�L(f��ng)�ư�|��һ�Q���@��(g��)��Ƹ��(bi��o)��(zh��n)���Ҷ��M(j��n)����(l��i)����н20W��С����(l��i)�� �����@Щ��(j��ng)�(y��n)�����f(shu��)�o�� (t��ng)���Ͼ��������13K�q��16K ��Ȼ����Ů�ώ����P(gu��n) (t��ng)��ǰ����һ����н15W��С����(l��i)�v����н�v���ˣ����H�����ң��ٲ���ؓ(f��)�ഺ�ˣ�19�î��I(y��)����ǰ�ҵ�������߀����н15W���ǷN����ţ�ˣ�܊���D(zhu��n)�Ё�(l��i)�W(xu��)Ƕ��ʽ���c�A��Y(ji��)�²���֮���A���h(yu��n)Ҋ(ji��n)90+�(xi��ng)Ŀ�@����������2021���
f(xi��)ͬ�����(xi��ng)Ŀ���A���h(yu��n)Ҋ(ji��n)�s�@2021�vӍ��������ȿڱ�Ӱ����I(y��)����Ʒ�A���h(yu��n)Ҋ(ji��n)��������2021����h���k��У��Ϣ�W(xu��)�ƺ���(li��n)����ůͬ�й���(chu��ng)�ѿ�(j��) 2019�A���h(yu��n)Ҋ(ji��n)�����������(hu��)���ع�������УAI�˹����܌W(xu��)�ƽ��O(sh��) �A���h(yu��n)Ҋ(ji��n)�˹������Y���A���h(yu��n)Ҋ(ji��n)���������Ĵ�ʡ��(li��n)�W(w��ng)���(hu��)���s�@��(y��u)����I(y��)����
11�¾͘I(y��)�L(f��ng)�ư�ح���н�Y18k����н11k�����¾͘I(y��)���c(di��n)ʮ�¾͘I(y��)�L(f��ng)�ư�ح�x���A�� ��н�͘I(y��)�����ܶ����@���¾͘I(y��)�L(f��ng)�ư� | �͘I(y��)�΄�(sh��)���ԣ��A��W(xu��)�Ӆs���(sh��)��������T�ܿɐ�(��i) ���YҲ���� 8��н�Y���t��һ�N���������e�˼ҵij���T����һ�N���YҲ�����e�����¾͘I(y��)�L(f��ng)�ư�|��һ�Q���@��(g��)��Ƹ��(bi��o)��(zh��n)���Ҷ��M(j��n)����(l��i)����н20W��С����(l��i)�� �����@Щ��(j��ng)�(y��n)�����f(shu��)�o�� (t��ng)���Ͼ��������13K�q��16K ��Ȼ����Ů�ώ����P(gu��n) (t��ng)��ǰ����һ����н15W��С����(l��i)�v����н�v���ˣ����H�����ң��ٲ���ؓ(f��)�ഺ�ˣ�19�î��I(y��)����ǰ�ҵ�������߀����н15W���ǷN����ţ�ˣ�܊���D(zhu��n)�Ё�(l��i)�W(xu��)Ƕ��ʽ���c�A��Y(ji��)�²���֮���A���h(yu��n)Ҋ(ji��n)90+�(xi��ng)Ŀ�@����������2021���
f(xi��)ͬ�����(xi��ng)Ŀ���A���h(yu��n)Ҋ(ji��n)�s�@2021�vӍ��������ȿڱ�Ӱ����I(y��)����Ʒ�A���h(yu��n)Ҋ(ji��n)��������2021����h���k��У��Ϣ�W(xu��)�ƺ���(li��n)����ůͬ�й���(chu��ng)�ѿ�(j��) 2019�A���h(yu��n)Ҋ(ji��n)�����������(hu��)���ع�������УAI�˹����܌W(xu��)�ƽ��O(sh��) �A���h(yu��n)Ҋ(ji��n)�˹������Y���A���h(yu��n)Ҋ(ji��n)���������Ĵ�ʡ��(li��n)�W(w��ng)���(hu��)���s�@��(y��u)����I(y��)����

